ディープラーニングの流れをさらっと再確認しよう!!
ディープラーニングの理解がいまいちだったため、整理するために全体の流れをまとめます。
かるく勉強したことある人を対象としているので、理論・用語・ライブラリなどの説明は省きます。
サンプルでは簡単な画像分類の学習を載せています。
ライブラリはKerasを使っています。
サンプルを動かす条件
最後にサンプルを載せていますが、実行できるようにするためには以下の準備が必要です。
①Python環境の構築
②必要ライブラリのインストール
①については以前に書いた以下の記事をご参照ください。
programming-lab.hatenadiary.com
②については①で構築した環境で以下のようにダウンロードしてください。
>conda install jupyter >conda install tensorflow >conda install keras
コーディングにはJupyterNotebookを使っています。
初めての方は以下の記事を参照してください。
programming-lab.hatenadiary.com
以上がそろえばサンプルコードが実行できる状態になります。
ディープラーニングの流れ
ディープラーニング全体の流れとしては以下のようになります。
1.データの前処理
2.ニューラルネットワークの作成
3.学習の設定
4.学習の実行
5.推論の実行
データの前処理
ニューラルネットワークに渡すデータの取得・加工を行う工程です。
〇やること
・学習用データの取得
・データの変形
ニューラルネットワークの作成
学習に使用するニューラルネットワークを作成します。
〇やること
・入力、中間、出力層の設定
・活性化関数の設定
学習の設定
学習する際に使う関数の設定などを行います。
〇やること
・損失関数(誤差関数)の設定
・最適化アルゴリズムの設定
学習の実行
作成したネットワークで学習を開始します。
〇やること
・バッチサイズ、エポック数等の設定
推論の実行
テストデータを使って学習がうまく進んでいるかをテストします。
サンプルコード
サンプルコードの全容を載せておきます。
#===================================
#インポート
#===================================
#数値演算用ライブラリ
import numpy as np
#Keras
from keras.layers import Input, Flatten, Dense
from keras.models import Model
from keras.optimizers import Adam
from keras.utils import to_categorical
#今回の学習データ取得に必要
from keras.datasets import cifar10
#===================================
#データの前処理
#===================================
#分類数
NUM_CLASSES = 10
#データ取得
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
#0~255のデータを0~1のfloat32型のデータに変形
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
//正解ラベルデータをOnHot表現に変換
y_train = to_categorical(y_train, NUM_CLASSES)
y_test = to_categorical(y_test, NUM_CLASSES)
#OnHot表現とは
#5種類のデータがある場合で2番目が正解だった場合
#通常1というデータが入っているが、OnHot表現に直すと
#(0,1,0,0,0)というベクトルになる
#===================================
#ニューラルネットワークのモデル作成
#===================================
#入力層
input_layer = Input((32,32,3))
#入力データを平坦化
x = Flatten()(input_layer)
#全結合層を2つ重ねる
#活性化関数はReLU
x = Dense(200, activation = 'relu')(x)
x = Dense(150, activation = 'relu')(x)
#出力数が分類の数になるように最後の層を設定
#活性化関数は出力を確率にするためソフトマックス関数
output_layer = Dense(NUM_CLASSES, activation = 'softmax')(x)
#モデルを作成
model = Model(input_layer, output_layer)
#===================================
#学習の設定
#===================================
#最適化アルゴリズムにAdamを使用。
opt = Adam(lr=0.0005)
#損失関数は交差エントロピー
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
#===================================
#学習
#===================================
model.fit(x_train
, y_train
, batch_size=32
, epochs=10
, shuffle=True)#データをシャッフルする
#===================================
#推論
#===================================
model.evaluate(x_test, y_test)
まとめ
ディープラーニングの流れをさらっと一通り見ていきました。
今回載せているサンプルはすべて全結合層を使った簡単な実装です。
3エポック学習した結果、正答率は50%程度でした。
画像解析の場合はCNNを使うとさらに正答率が上がりますが、今回はシンプルさを重視しました。
WebブラウザでPythonプログラムを作成!!JupyterNotebookの導入から使い方まで
プログラムを書く時にはコーディングや実行を行う環境が必要です。
今回はWebブラウザでコーディングから実行まで行うことができる、「JupyterNotebook」の導入と使い方を書いていきます。
読み方は「ジュピターノートブック」です。
JupyterNotebookはPython以外の言語でも使えます。
- 前提条件
- JupyterNotebookのインストール方法
- Pythonプログラムを置くフォルダに移動
- JupyterNotebookを起動する
- Pythonファイルを作成
- プログラムを書いてみる
- JupyterNotebookを終了する
- まとめ
前提条件
今回はAnaconda環境で説明していきます。
使いたい仮想環境をアクティベートした状態で以下の設定を進めていってください。
何のこと?という方は以下の記事を見ながら設定をしてもらえればと思います。
programming-lab.hatenadiary.com
JupyterNotebookのインストール方法
AnacondaPromptを開いて以下のコマンドを実行します。
>conda install jupyter
いろいろ文字が出てきた後に
Proceed([y]/n)?
と表示されるので「y」を入力して、エンターを押してください。
するとインストールが開始されます。
エラーが出なければインストール成功です。
これでJupyterNotebookを使えるようになりました!
Pythonプログラムを置くフォルダに移動
AnacondaPromptはデフォルトでカレントディレクトリがユーザーフォルダになっているはずです。
カレントディレクトリは下の画像の場所で確認できます。

ここをPythonプログラムを置くフォルダに変更します。
これをしないとJupyterNotebookを開いたときにプログラムを作りたいフォルダに作れません。
まだフォルダがないという人は今から作りましょう。
場所はどこでもいいのですが、今回はわかりやすいようにCドライブ直下に作りました。

それではAnacondaPromptでこのフォルダまで移動しましょう。
以下のコマンドを実行してください
>cd C:\Python
これでカレントディレクトリが先ほど作ったPythonフォルダに変わったと思います。
JupyterNotebookを起動する
AnacondaPrompt上で以下のコマンドを実行してください
>jupyter notebook
すると以下のような画面が開きます。
 この画面には起動した際のカレントディレクトリのフォルダ内容が表示されます。
この画面には起動した際のカレントディレクトリのフォルダ内容が表示されます。
先ほど作成したフォルダは何も入っていないので、JupyterNotebook上でも何も表示されません。
Pythonファイルを作成
それではPythonファイルを作成しまししょう。
画像の赤で囲っている部分を順にクリックしてください。 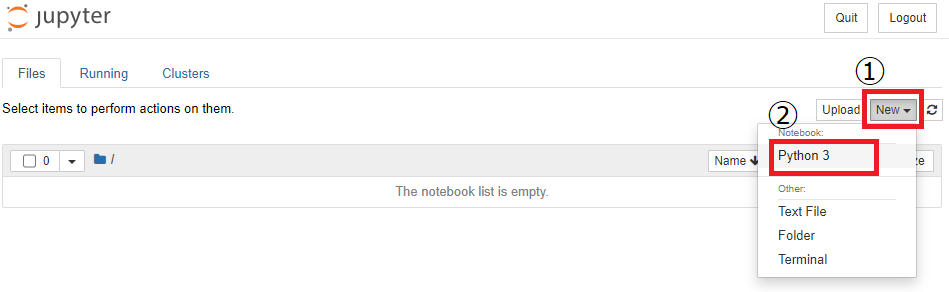 すると新しい画面が開きます。
すると新しい画面が開きます。
 ここにPythonコードを書いていきます。
ここにPythonコードを書いていきます。
先ほど作ったPythonフォルダを見てみるとJupyterNotebookで作ったファイルが追加されています。
 「Untitled.ipynb」というファイルが作ったPythonファイルです。
「Untitled.ipynb」というファイルが作ったPythonファイルです。
「.ipynb_checkpoints」はJupyterNotebookの状態を記憶しているファイルです。
セーブファイルのようなもので、今は気にしなくて大丈夫です。
Pythonファイルの名前はデフォルトで「Untitled」になっています。
変更する場合は画像の赤枠の場所をクリックすると変更することができます。
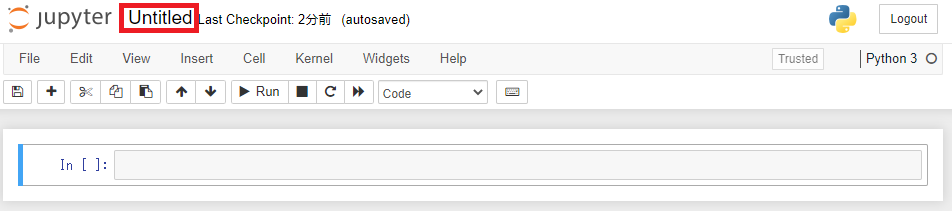
プログラムを書いてみる
作成したファイル上のグレーの四角い領域にプログラムを書いていきます。
プログラムを書く領域をセルと呼び、プログラムを実行する単位となります。
セルは「Alt」+「Enter」または「Shift」+「Enter」で増やすことができます。
また不要なセルは選択した状態で、画面上部のはさみアイコンをクリックすると削除できます。
プログラムはセルごとに実行されるので途中経過を確認したりできます。
それではテストでPythonプログラムを書いてみましょう!
以下の画像のプログラムを書いてみてください。
 書き終えたら「Shift」+「Enter」または上部のRunボタンを押してみましょう。
書き終えたら「Shift」+「Enter」または上部のRunボタンを押してみましょう。
 すると1つ目のセルで計算した結果が出力されました!
すると1つ目のセルで計算した結果が出力されました!
JupyterNotebookを終了する
プログラムを書き終えて終了するときは、AnacondaPromptに戻り「Ctr」+「C」を押します。
少しするとJupyterNotebookが終了します。
Webブラウザに戻ってリロードすると、ページにアクセスできなくなっています。
再開するときは最初と同じようにコマンドを実行してください。
>jupyter notebook
まとめ
JupyterNotebookの一連の流れを見ていきました。
Pythonを使う場合よく使われる環境なので、知っておくと役立つと思います
強化学習を始めよう!!その1~環境構築編~
強化学習を使ったゲームのデバッグをやってみたいので強化学習を勉強し始めました。
自分の覚書もかねてやり方などを書いていきたいと思います。
最終的にはUEで強化学習するところまで行く予定です。
1回目は環境構築をやっていきます!
使う言語はPythonなのでAnacondaを使ってPythonの環境構築をしていきたいと思います。
ちなみに環境とはpythonのバージョン、ライブラリの種類・バージョンなどの状態の総称です。
- Anacondaとは?
- 環境構築の流れ
- Anacondaのインストール
- 仮想環境の構築
- 仮想環境を切り替える
- 必要なライブラリのインストール
- ライブラリの確認
- JupyterNotebookを開いてみる
- まとめ
Anacondaとは?
Pythonを使って開発を進めていく場合、多くのライブラリをインストールします。
また開発に応じて環境を作り、必要なライブラリだけをインストールした状態の環境を作ります。
こういった作業はめんどくさく、初めての人にとっては難しい作業です。
Anacondaはそうした環境構築の手助けをしてくれるサービスです。
機械学習やデータサイエンスなどの分野では定番でよく使われているようです。
環境構築の流れ
以下の3つを行うと開発できる状態に持っていくことができます。
1. Anacondaのインストール
2. 仮想環境の構築
3. 必要なライブラリのインストール
ちなみに仮想環境とは1つのパソコンの中に複数の環境を用意して、
ある環境を使うときにはまるでその1つの環境しかないように思わせることです。
最初はめんどくさく感じますが、慣れれば簡単です!
それでは順に説明していきたいと思います。
Anacondaのインストール
インストールは以下のサイトからできます
www.anaconda.com
ダウンロードしたファイルを実行してデフォルトの設定のままインストールします。
注意点としては、ユーザー名に日本語が入っている場合はエラーが出る可能性があります。
デフォルトではユーザーフォルダにインストールされるので、日本語が入っている人はインストール場所を変更しましょう。
その場合はCドライブ直下とかにインストールするといいと思います。

ユーザー名が英数字の場合はデフォルトままでOKです!
インストールが完了し「finish」ボタンを押すと、Webのチュートリアルページが開きます。
興味のない人はそっと閉じましょう。
仮想環境の構築
次に仮想環境を作っていきましょう。
まずは「Anaconda Prompt」というファイルを開きましょう。
Anacondaのインストールしたときに一緒にインストールされています。
コマンドプロンプトと同様な黒いコンソールウィンドウが出てくると思います。

この画面上でAnaconda環境を整えていきます。
(通常のコマンドプロンプトでもPathを通していたらできますが、公式が非推奨にしています)
それではさっそく新しい仮想環境を作ってみたいと思います。
conda create -n 【環境名】 python=【Pythonバージョン】
【環境名】には作成したい仮想環境の名前を入れます。
私は強化学習用の環境なので「rl_env」にしました。
【Pythonバージョン】にはバージョンの数値を入れます。
私は「3.7」で作成しました。
エンターを押すと仮想環境の作成が開始します。
少しすると確認が出てくるので「y」キーを押してエンターで続行します。

エラーがでなければ仮想環境の作成成功です!
仮想環境を切り替える
先ほど作成した仮想環境にライブラリをインストールしたいため、環境を切り替える必要があります。
現状は最初からある環境(Root環境)になっているので、作成した仮想環境に切り替えます。
以下のコマンドで切り替えることができます。
conda activate 【環境名】
すると以下のように先頭のカッコ内が切り替えた環境名に代わります。
 これで環境の切り替えが完了しました。
これで環境の切り替えが完了しました。
ちなみに環境を削除したい場合は以下のコマンドで削除できます。
conda remove --name 【環境名】 --all
必要なライブラリのインストール
それではライブラリインストールしていきたいと思います。
今回は環境構築編なので、強化学習で必要なライブラリのインストールは次回以降に回します。
今回はJupyterNotebookというライブラリだけインストールしたいと思います。
JupyterNotebookはWebブラウザでPythonを実装・実行できるライブラリです。
以下のコマンドでライブラリをインストールすることができます。
pip install 【ライブラリ名】
今回の場合は以下のようなコマンドを入れます。
pip install jupyter
エラーが出なければインストール成功です!
ライブラリの確認
現在インストールされているライブラリを確認しておきましょう。
以下のコマンドで現在インストールしているライブラリを確認できます。
conda list
先ほど入れたJupyterNotebook以外にも初期からいくつかのライブラリが入っています。
赤で囲っているJupyter関連のライブラリが確認できればOKです!

JupyterNotebookを開いてみる
それではインストールしたJupyterNotebookを起動してみましょう。
以下のコマンドを実行してみてください
jupyter notebook
すると以下のようなWebブラウザが開かれると思います。
 このページでPythonプログラムを作成していきます。
このページでPythonプログラムを作成していきます。
詳しい使い方などは次回以降に説明していきたいと思います。
JupyterNotebookを起動している間はほかのAnaconda上でほかの操作をすることができません。
ブラウザを閉じただけでは終了できず、AnacondaPromptで「Ctr」+「C」を押す必要があります。
まとめ
今回は環境構築編ということでAnacondaを使った開発環境の構築方法を書いてみました。
次回以降は実際に強化学習をやっていきたいと思います。
自分も勉強中なので投稿は遅くなるとは思いますが、一緒に勉強していきましょう!
ツイッターに途中経過などを投稿するので是非見てくださいね!
環境構築なし!!Web上で手軽にPythonを実装&実行できる「TryJupyter」を使ってみた
通常Pythonを使う場合は自分のPC上に環境を構築しなければなりません。
しかし、初心者の方の場合環境構築でつまずくことや、難しいと感じることが多いと思います。
そこで、とりあえずPythonを体験したいという人にお勧めなのがTryJupyterというサービスです。
TryJupyterとは
TryJupyterとは一言でいえば、Web上でプログラムを実装・実行できるサービスです。
巷にはJupyterNotebookというPythonなどのプログラム言語を便利に実装できるサービスがあります。
それと同じものをWeb上で使えるのがTryJupyterとなっています。
サクッとお試しでPythonを体験したときなどにはピッタリのサービスですね。
TryJupyterの使い方
TryJupyterのページを開く
以下のリンクからTryJupyterのページに飛べます。
JupyterNotebookを開く
「TryClassicNotebook」をクリックするとJupyterNotebookが開きます

新規ファイルの作成
JupyterNotebookが開いたのでPythonコードを記述するための、新規ファイルを作成します。
左上の「File」>「NewNotebook」>「Python3」をクリック。
すると新しいページが開き、ファイルが作成される。

プログラムを書き込む
作成したファイル上のグレーの四角い領域にプログラムを書いていきます。
この領域をセルと呼び、プログラムを実行する単位となります。
セルは「Alt」+「Enter」または「Shift」+「Enter」で増やすことができます。
また不要なセルは選択した状態で、画面上部のはさみアイコンをクリックすると削除できます。
セルごとに実行されるのでプログラムの途中経過を確認したりできます。

Pythonプログラムを書いてみる
それではテストでPythonプログラムを書いてみましょう!
以下の画像のプログラムを書いてみてください

書き終えたら「Shift」+「Enter」または上部のRunボタンを押してみましょう。

すると1つ目のセルで計算した結果が出力されました!
プログラムを保存
先ほど作成したコードを保存しましょう。
ファイルの名前を変える
上部の「Untitled」と書いてある部分をクリックします。

すると以下のような画面が表示されますので、ボックス内の名前を変えましょう。
今回は「PythonTest」にしました。
右下のRenameボタンを押すとファイル名の変更が完了します。

ファイルをダウンロード
上部の「ファイル」>「Download as」>「Noteboook(.ipynb)」を選択します。
すると先ほどつけた名前のファイルが保存されます。

保存したファイルを読み込む
画面左上の「Jupyter」のロゴの部分をクリックします。

すると以下のような画面が開きます。
これがホーム画面でここに先ほどダウンロードしたものをアップロードします。
右上のUploadボタンを押すとエクスプローラーが開くので、先ほど保存したファイルを選択します。

すると、選択したファイル名が出てくるので右側のUploadボタンを押しましょう。

これでアップロード完了です。
クリックすると、先ほどと同じプログラムの画面が出てくると思います。
まとめ
以上がTryJupyterを使ってWeb上でPythonプログラムを作成する方法でした。
ちなみにTryJupyterはブラウザごとにファイルを管理しています。
なので、保存したものを他のブラウザで起動しようとしてもできません。
その場合またアップロードをする手順がいります。
あくまで簡単にPythonを試してみる用途での使用で、バリバリ開発するには向いていません。
しかし、手軽にPythonを体験したい場合にはかなり便利なサービスなのではないでしょうか?
Pythonを触ってみたいという人はまず、TryJupyterを使ってみるのをお勧めします!
【UE4】バージョン管理システムは何を使う?Git・SVN・Perforceを比較!
ゲームを作るとなれば、ほぼ間違いなくバージョン管理を行いますよね。
バージョン管理システムといえばGit・SVNなどいくつかの選択肢がありますが
UE4で使う場合どれが最適なのか調べてみました。
結論
結論から言うと、僕はGitを使うことにしました。
Gitはバイナリファイルの管理に弱いので、GitLFSという機能も併用して使います。
それでは詳しく見ていきましょう。
UE4で使えるバージョン管理システム
まずUE4が対応しているバージョン管理ステムをご紹介します。
Git
現状もっとも使われているであろうバージョン管理システム。
分散型でローカルリポジトリがあるため、慣れていれば使いやすい。
バイナリファイルの管理に弱い。
Subversion(SVN)
集中型なのでローカルリポジトリがないが、直感的で理解しやすい。
リビジョンも連番でわかりやすい。
バイナリを差分で管理できる。
Perforce(P4)
SVNと同じく集中型。
SVNは作業コピーをローカルに持っていますが、P4はデータベース上に保存している。
そのため更新などの速度が段違いで早いらしい。
UE4で使うにはどれがいいの?
それぞれに長所・短所があります。
なので、UEで使う上でのざっくりとしたメリット・デメリットを書いていきます。
僕自身そんなに詳しいわけではないので、個人の見解ということでご覧ください。
Git
メリット
デメリット
- バイナリファイルが差分管理できないので容量がでかくなりがち
- UEのソースコントロールがまだβ版
Subversion(SVN)
メリット
デメリット
- ローカルコミットができない
- ブランチに制約が多い
- ホスティングサービスにいいのが見当たらない(※個人の意見です)
Perforce(P4)
メリット
- SVNより高速に処理できるらしい
- UEで有名な会社ヒストリアさんも使ってる
メリット
- 情報がすくない
- お金がかかる(無料版はいろいろ制限があるらしい)
結局どれを使うか?
Perforceはだいぶプロ仕様っぽかったので今回はパスですね。
正統派で行けばSVNを使うのが妥当なんだと思います。
(バイナリに強い&ソースコントロールも正式版のため)
しかし、自分は
という理由からGitを使うことにしました。
ただ、BPなどのuassetがバイナリファイルのため、差分管理できない点が痛いです。
そこで、GitLFSという機能を使うことで回避したいと思います。
GitLFSとは簡単に言うと
「バイナリファイルを別の場所で管理して、Git上ではハッシュ値だけ管理する。
なので、リポジトリの容量は減る」
という機能です。
また、GitLFSを使うと一応ロック機能も使えるようになります。
ロック機能に関してはSVNより制限があります。
ちゃんとルールを決めておかないと普通に競合するので少し使い勝手は悪そうでした。
ですが、Gitの構造上仕方がないことなのでそこはがまんします。
(まぁチームメンバーが少ないので、そこまでロック機能使わないし…)
まとめ
一応これでGit上でUE4のプロジェクトを管理することができそうです。
もっといい方法を知っている方がいれば、ぜひ教えてください!